1. 写在前面
模型(推理模型)分为预测模型和识别模型,模型拿到数据需要先使用预测模型将文本框选出来,然后再使用识别模型来识别文本
训练模型总体分为4个步骤:第一步:标注数据,并生成相关配置文件 第二步:训练预测模型 第三步:训练识别模型 第四步:将两个模型导出为推理模型
首先标注数据使用PPOCRLabel,将准备好的图片打开,可以使用自动标注将图片中需要识别的文本标注出来,然后人工修改模型预测错的数据,也可以直接自己框选并写入数据
可以从训练曲线中参考到训练模型过程中模型在识别时学习的过程
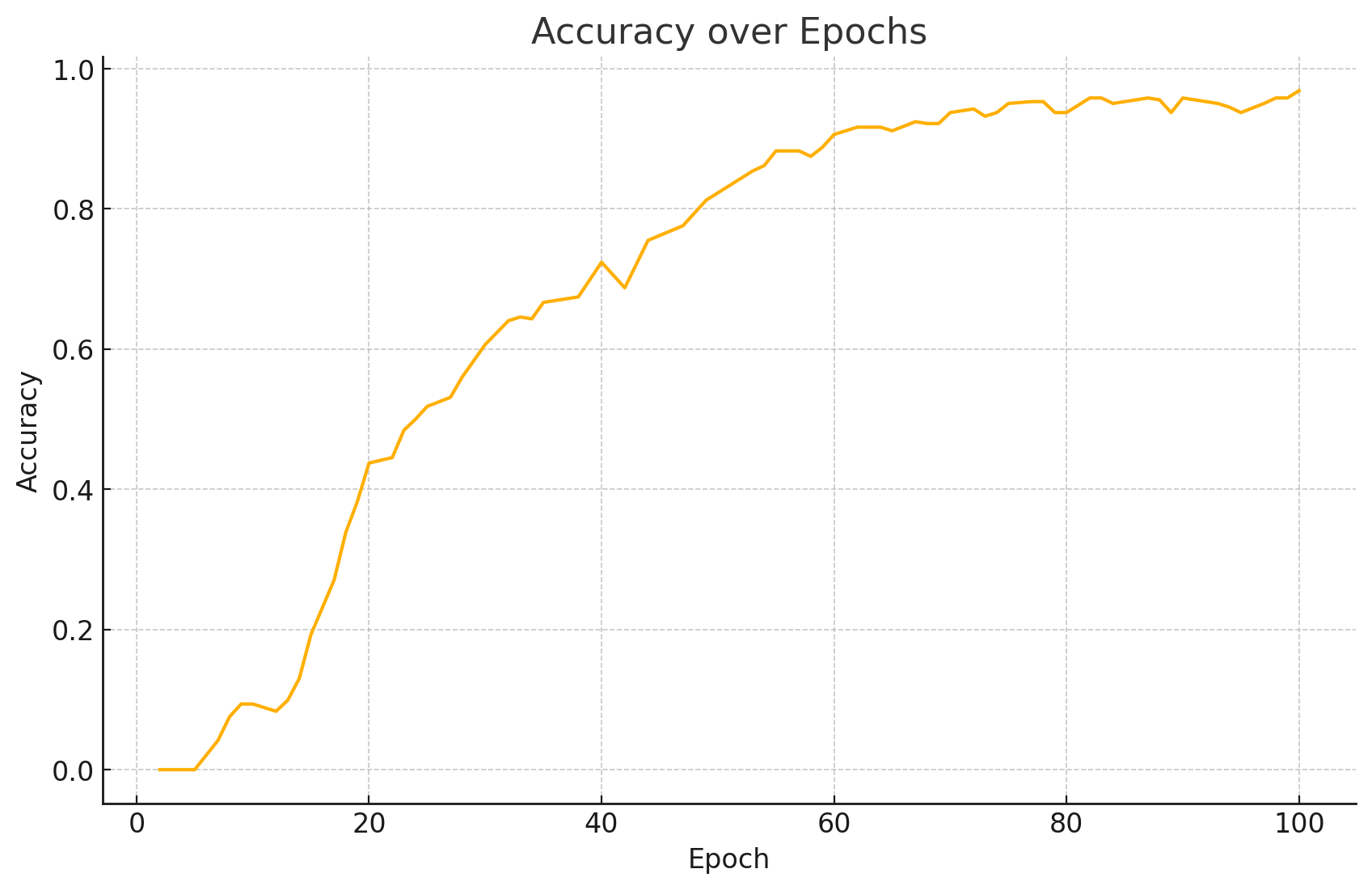
1. 准确率 (Accuracy)
在训练一百轮中,整体表现稳定提升,说明模型学习效果不断增强。
2. 总损失(Loss)
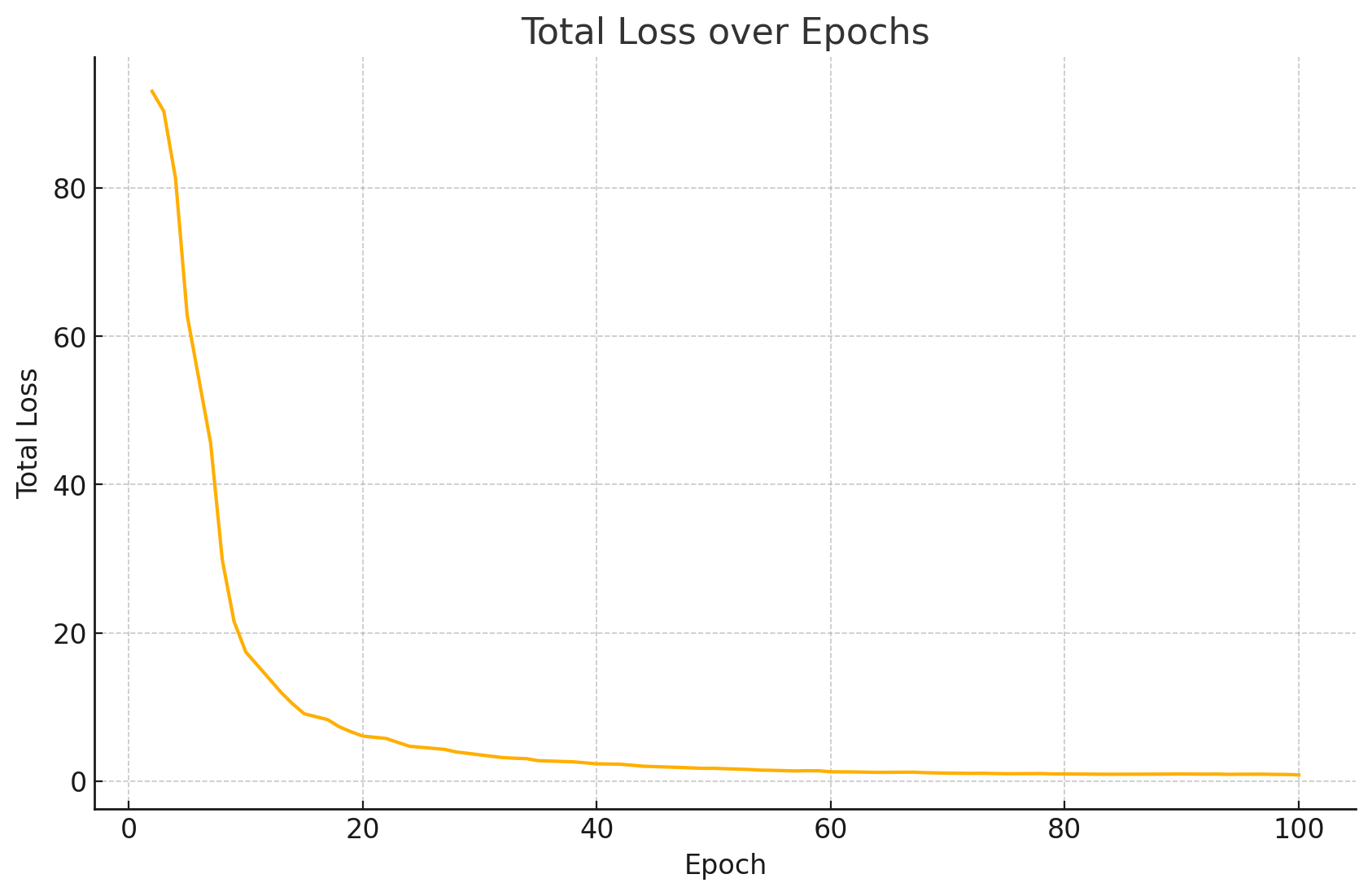
Loss:模型在一次前向计算后,所有任务(子损失)误差的加权和。它反映了模型整体预测结果与真实标签之间的差距。
$Total Loss = CTCLoss + NRTRLoss$
第 2 轮约 93,迅速降到第 10 轮 ~17,然后平滑下降到第 50 轮 ~1.7,再到第 100 轮 ~0.85。训练初期收敛最快,中后期趋于平缓。
3. CTCLoss
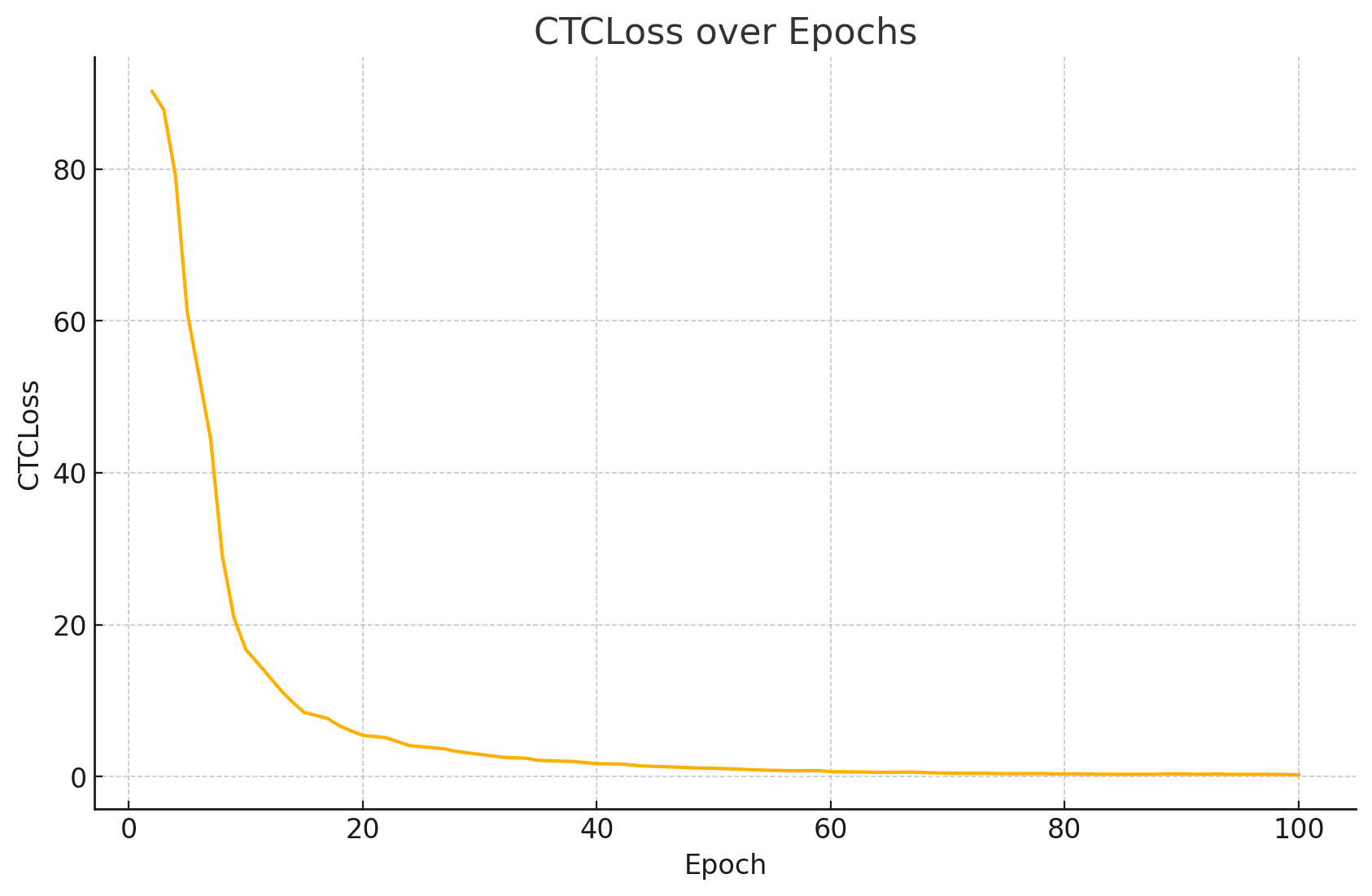
CTCLoss:它惩罚模型把字符预测到错误的时刻或多余的空白,数值越小说明模型在序列对齐和字符识别上越准确。
从 ~90 降到 ~0.23,第 10–20 轮后就降至个位数,第 40 轮后接近 1,至第 100 轮降至 ~0.23。
是整体 loss 降低的主力。
4. 归一化编辑距离 (Norm Edit Distance)
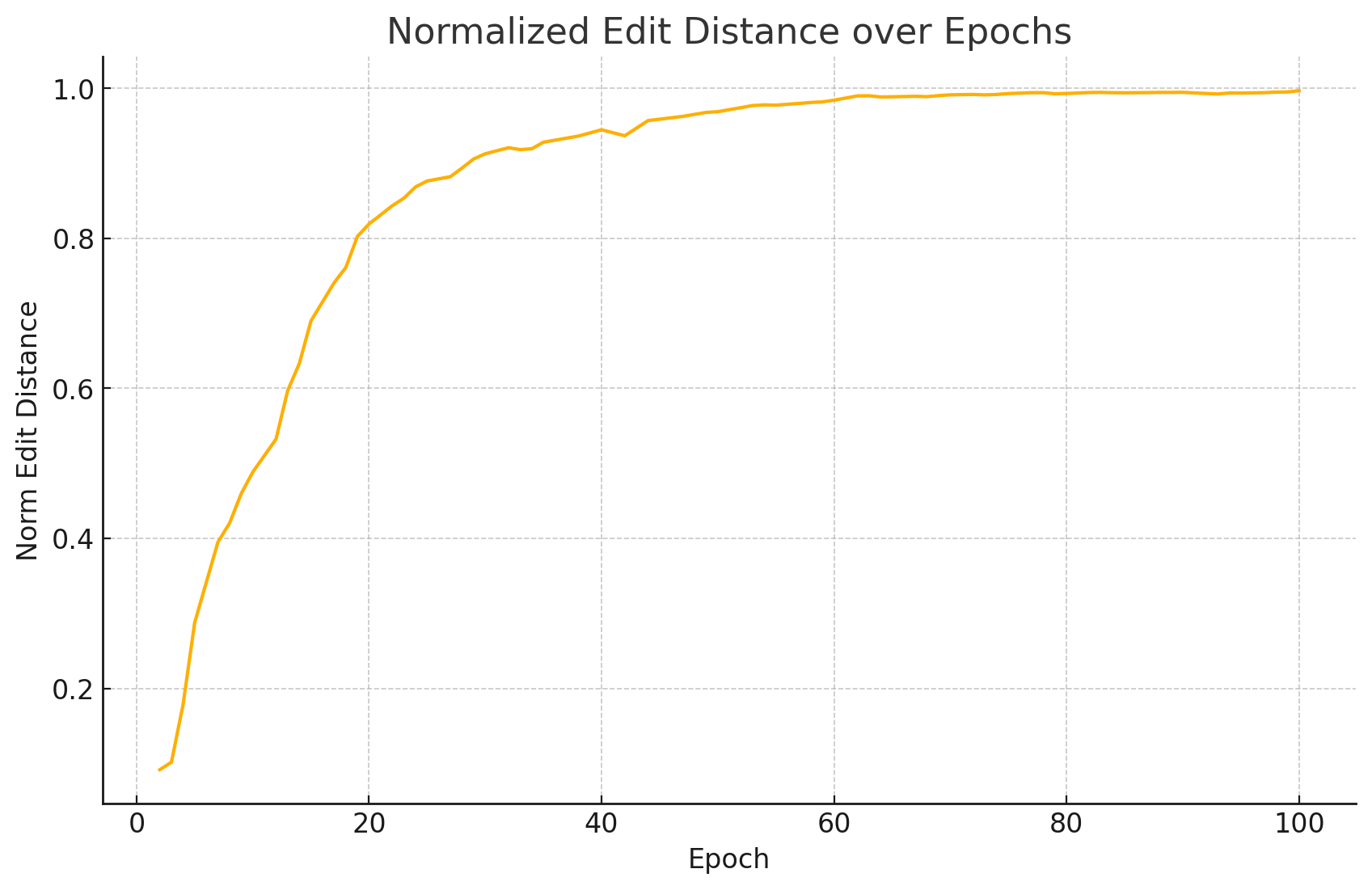
编辑距离:衡量预测文本和真实文本在字符层面需要多少次“增删改”操作才能互相转换。
归一化:用编辑距离除以真实文本长度,得到一个 0–1 之间的比值。如果值越接近0,表示预测文本与真实文本差异越小,预测的越准确。
第 30+ 轮后即超过 0.90,到第 60 轮接近 0.98,表明预测文本与真实文本高度一致。
5. 模型收敛
收敛 是训练进入“平稳”阶段,模型已基本学到数据规律,还未出现明显分歧。
在训练开始时,损失(Loss)通常会快速下降,准确率迅速上升;当训练到一定轮数后,指标变化变得非常缓慢,曲线趋于平稳,这种状态就叫“收敛”
即模型已经基本学到了数据中的规律,再继续训练改进也会很有限。
训练模型到”收敛“的时候表明训练达到了最佳或接近最佳状态,可以考虑停止训练、保存模型,或者改用更细的学习率再做微调。
如果epoch_num(迭代次数)过高,会导致模型过拟合
6. 过拟合
过拟合 是训练和泛化能力开始脱钩,虽然训练集表现更好,但验证/测试集性能变差,需加以干预。
过拟合示例:
- 训练 loss 从 0.5 → 0.2 → 0.1 → 0.05;验证 loss 从 0.6 → 0.3 → 0.25 → 0.35。
- 验证 loss 在第三次迭代后回升,说明模型开始记忆训练集噪声,泛化能力下降。
过拟合会导致什么?
正常学习:你看了很多苹果、香蕉、橙子的照片,还是真实的水果。考试时,给你没见过角度的苹果、香蕉、橙子,你都能认出来——这就是「泛化好」,模型没过拟合。
过拟合:你只记住了教科书里那几张苹果、香蕉、橙子的照片的每一个细节(比如苹果旁边那片叶子的形状、香蕉背景的光线角度),连截图里边的阴影都背下来了。但考试时给你一张真实市场上卖的苹果照片,因为背景不同、光线不同,你反而认不出这是苹果了。——模型把训练集(教科书图片)记得滚瓜烂熟,却学不到“苹果是圆圆的、有柄、红色或青色”这个本质,就叫过拟合。
过拟合就像死记硬背教科书上的样本,而不是理解背后的规律,结果一遇到新场景就傻眼。
判定依据:
- Loss 曲线趋于平缓:每个 epoch 的 loss 下降很少。
- Accuracy / norm_edit_dis 曲线趋于平稳:指标几乎不再提升。
2. 训练步骤
2.1 标注数据
ppocrlabel安装位置
D:\\anaconda3\\envs\\paddle38\\lib\\site-packages
安装路径
C:\\Users\\wa1yb\\.conda\\envs\\paddle39\\Lib\\site-packages\\PPOCRLabel>
启动命令
python PPOCRLabel.py --lang ch
将数据集划分(训练集/验证集/测试集)
**python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 –-datasetRootPath ./train_data --detRootPath ./train_data/det --recRootPath ./train_data/rec**
参数说明:
-
trainValTestRatio 是训练集、验证集、测试集的图像数量划分比例,根据实际情况设定,默认是6:2:2
-
datasetRootPath 是PPOCRLabel标注的完整数据集存放路径。默认路径是 …/train_data/
就是步骤6的结果文件夹train_data文件夹。
-
detRootPath 是输出训练文字检测的数据集存放路径。默认路径是 …/train_data/det
-
recRootPath 是输出训练文字识别的数据集存放路径。默认路径是 …/train_data/rec
2.2 训练检测模型
2.2.1 修改配置文件
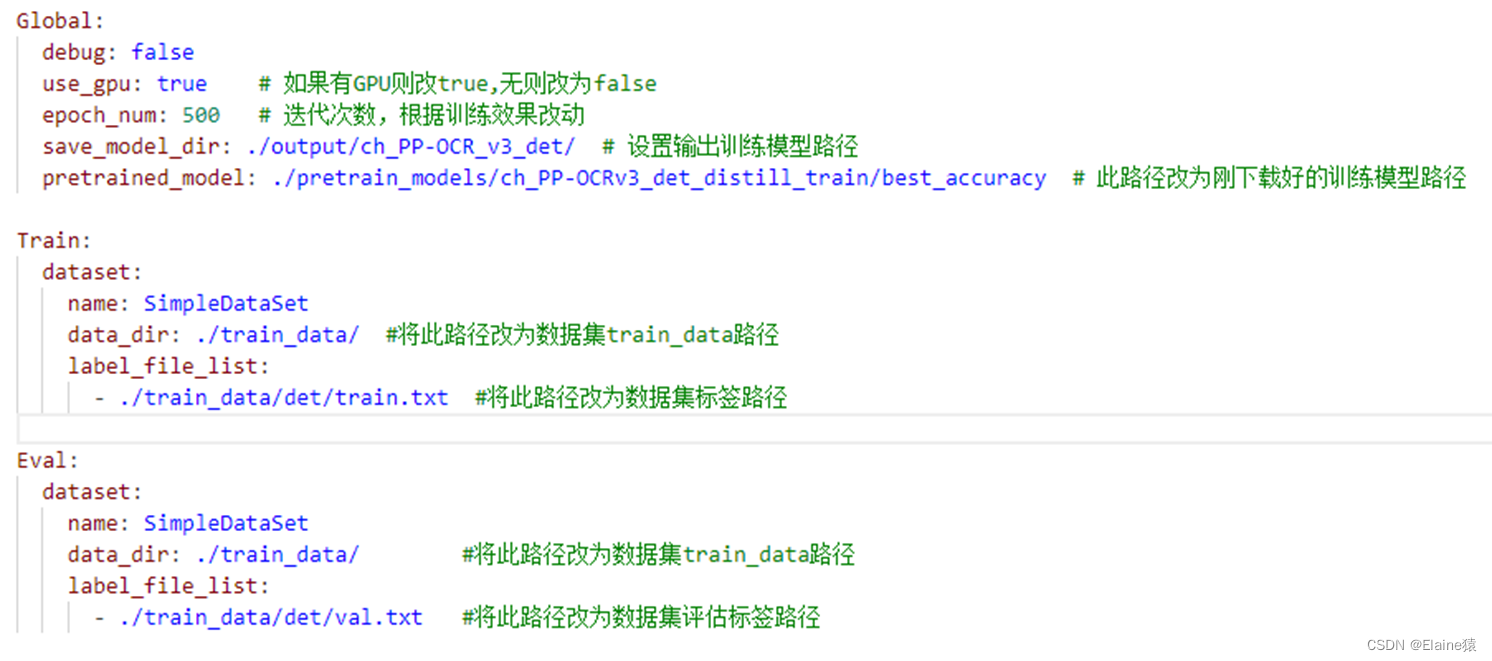
配置文件
Global:
debug: false
use_gpu: true
epoch_num: 300 # 迭代次数
log_smooth_window: 20
print_batch_step: 10
save_model_dir: ./output/en_PP-OCRv3_det/
pretrained_model: ./Temp/myModel/en_PP-OCRv3_det/latest
save_epoch_step: 5
eval_batch_step:
- 0
- 100 # 验证频率 只在最后评估 让训练连续进行更久
cal_metric_during_train: false
checkpoints: null
save_inference_dir: null
infer_img: ./Temp/testImage/
save_res_path: ./checkpoints/det_db/predicts_db.txt
distributed: true
d2s_train_image_shape: [3, -1, -1]
amp_dtype: bfloat16
# amp_dtype: float16
Architecture:
name: DistillationModel
algorithm: Distillation
model_type: det
Models:
Student:
pretrained:
model_type: det
algorithm: DB
Transform: null
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
disable_se: true
Neck:
name: RSEFPN
out_channels: 96
shortcut: True
Head:
name: DBHead
k: 50
Student2:
pretrained:
model_type: det
algorithm: DB
Transform: null
Backbone:
name: MobileNetV3
scale: 0.5
model_name: large
disable_se: true
Neck:
name: RSEFPN
out_channels: 96
shortcut: True
Head:
name: DBHead
k: 50
Teacher:
freeze_params: true
return_all_feats: false
model_type: det
algorithm: DB
Backbone:
name: ResNet_vd
in_channels: 3
layers: 50
Neck:
name: LKPAN
out_channels: 256
Head:
name: DBHead
kernel_list: [7,2,2]
k: 50
Loss:
name: CombinedLoss
loss_config_list:
- DistillationDilaDBLoss:
weight: 1.0
model_name_pairs:
- ["Student", "Teacher"]
- ["Student2", "Teacher"]
key: maps
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
- DistillationDMLLoss:
model_name_pairs:
- ["Student", "Student2"]
maps_name: "thrink_maps"
weight: 1.0
key: maps
- DistillationDBLoss:
weight: 1.0
model_name_list: ["Student", "Student2"]
balance_loss: true
main_loss_type: DiceLoss
alpha: 5
beta: 10
ohem_ratio: 3
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.001
warmup_epoch: 2
regularizer:
name: L2
factor: 5.0e-05
PostProcess:
name: DistillationDBPostProcess
model_name: ["Student"]
key: head_out
thresh: 0.3
box_thresh: 0.6
max_candidates: 1000
unclip_ratio: 1.5
Metric:
name: DistillationMetric
base_metric_name: DetMetric
main_indicator: hmean
key: "Student"
Train:
dataset:
name: SimpleDataSet
data_dir: ./Temp/train_data/images
label_file_list:
- ./Temp/train_data/det/train.txt
ratio_list: [1.0]
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- DetLabelEncode: null
- CopyPaste:
- IaaAugment:
augmenter_args:
- type: Fliplr
args:
p: 0.5
- type: Affine
args:
rotate:
- -10
- 10
- type: Resize
args:
size:
- 0.5
- 3
- EastRandomCropData:
size:
- 960
- 960
max_tries: 50
keep_ratio: true
- MakeBorderMap:
shrink_ratio: 0.4
thresh_min: 0.3
thresh_max: 0.7
- MakeShrinkMap:
shrink_ratio: 0.4
min_text_size: 8
- NormalizeImage:
scale: 1./255.
mean:
- 0.485
- 0.456
- 0.406
std:
- 0.229
- 0.224
- 0.225
order: hwc
- ToCHWImage: null
- KeepKeys:
keep_keys:
- image
- threshold_map
- threshold_mask
- shrink_map
- shrink_mask
loader:
shuffle: true
drop_last: false
batch_size_per_card: 8
num_workers: 4
Eval:
dataset:
name: SimpleDataSet
data_dir: ./Temp/train_data/images
label_file_list:
- ./Temp/train_data/det/val.txt
transforms:
- DecodeImage: # load image
img_mode: BGR
channel_first: False
- DetLabelEncode: # Class handling label
- DetResizeForTest:
- NormalizeImage:
scale: 1./255.
mean: [0.485, 0.456, 0.406]
std: [0.229, 0.224, 0.225]
order: 'hwc'
- ToCHWImage:
- KeepKeys:
keep_keys: ['image', 'shape', 'polys', 'ignore_tags']
loader:
shuffle: False
drop_last: False
batch_size_per_card: 1 # must be 1
num_workers: 2
2.2.2 启动训练
在PaddleOCR-release-2.8.1根目录下,执行命令开始训练:
python .\\tools\\train.py -c .\\Temp\\configs\\en_PP-OCRv3_det_cml.yml
2.2.3 测试模型
测试训练好的检测模型检测图片是否准确
python tools/infer_det.py -c .\\Temp\\configs\\en_PP-OCRv3_det_cml.yml -o Global.pretrained_model=/output/en_PP-OCR_v3_det/latest.pdparams Global.infer_img="D:\\Files\\PythonProject\\Important final code\\PaddleOCR-3.0.2\\testImages\\001.png"
测试导出后的检测模型 检测图片是否准确
python .\\tools\\infer\\predict_det.py --det_model_dir="./inference_model/v3det_model/Student" --image_dir="./Temp/testImages/003.png" --use_gpu=true
2.3 训练识别模型
配置文件
Global:
debug: false
use_gpu: true
epoch_num: 300
save_model_dir: ./output/en_PP-OCRv4_rec
pretrained_model: ./Temp/en_PP-OCRv4_rec_train/best_accuracy
# checkpoints: ./output/en_PP-OCRv4_rec/latest
checkpoints: null
log_smooth_window: 20
print_batch_step: 10
save_epoch_step: 10
eval_batch_step:
- 0
- 9999999
cal_metric_during_train: true
save_inference_dir: null
use_visualdl: false
infer_img: ./Temp/testImage/
character_dict_path: ppocr/utils/en_dict.txt
max_text_length: 25
infer_mode: false
use_space_char: true
distributed: true
save_res_path: ./output/rec/predicts_ppocrv3.txt
Optimizer:
name: Adam
beta1: 0.9
beta2: 0.999
lr:
name: Cosine
learning_rate: 0.0005
warmup_epoch: 5
regularizer:
name: L2
factor: 3.0e-05
Architecture:
model_type: rec
algorithm: SVTR_LCNet
Transform: null
Backbone:
name: PPLCNetV3
scale: 0.95
Head:
name: MultiHead
head_list:
- CTCHead:
Neck:
name: svtr
dims: 120
depth: 2
hidden_dims: 120
kernel_size:
- 1
- 3
use_guide: true
Head:
fc_decay: 1.0e-05
- NRTRHead:
nrtr_dim: 384
max_text_length: 25
Loss:
name: MultiLoss
loss_config_list:
- CTCLoss: null
- NRTRLoss: null
PostProcess:
name: CTCLabelDecode
Metric:
name: RecMetric
main_indicator: acc
ignore_space: false
Train:
dataset:
name: MultiScaleDataSet
ds_width: false
data_dir: ./Temp/train_data/images
ext_op_transform_idx: 1
label_file_list:
- ./Temp/train_data/rec/train.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- RecConAug:
prob: 0.5
ext_data_num: 2
image_shape:
- 48
- 320
- 3
max_text_length: 25
- RecAug: null
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
sampler:
name: MultiScaleSampler
scales:
- - 320
- 32
- - 320
- 48
- - 320
- 64
first_bs: 96
fix_bs: false
divided_factor:
- 8
- 16
is_training: true
loader:
shuffle: true
batch_size_per_card: 16
drop_last: true
num_workers: 8
Eval:
dataset:
name: SimpleDataSet
data_dir: ./Temp/train_data/images
label_file_list:
- ./Temp/train_data/rec/val.txt
transforms:
- DecodeImage:
img_mode: BGR
channel_first: false
- MultiLabelEncode:
gtc_encode: NRTRLabelEncode
- RecResizeImg:
image_shape:
- 3
- 48
- 320
- KeepKeys:
keep_keys:
- image
- label_ctc
- label_gtc
- length
- valid_ratio
loader:
shuffle: false
drop_last: false
batch_size_per_card: 16
num_workers: 4
profiler_options: null
启动训练
python tools/train.py -c .\\Temp\\configs\\en_PP-OCRv4_rec.yml
测试训练好的识别模型检测图片是否准确
python tools/infer_rec.py -c .\\Temp\\configs\\en_PP-OCRv4_rec.yml -o Global.pretrained_model=.\\output/en_PP-OCRv4_rec/best_accuracy.pdparams Global.infer_img="D:\\Files\\PaddleOCR-2.8.1\\Temp\\testImages\\577.png"
评估性能
在训练过程中可以及时对已经训练好的模型进行评估模型效果
在验证集上评估已经训练好的模型的性能表现,不继续训练,仅计算准确率、编辑距离和损失值等指标。
python .\\tools\\eval.py -c .\\Temp\\configs\\en_PP-OCRv4_rec.yml -o Global.checkpoints=.\\output\\en_PP-OCRv4_rec\\latest
2.4 导出推理模型
分别将上面训练好的检测、识别模型导出为推理模型
- 导出检测模型
python .\\tools\\export_model.py -c .\\Temp\\configs\\en_PP-OCRv3_det_cml.yml -o Global.pretrained_model=.\\Temp\\output\\en_PP-OCRv3_det\\latest Global.save_inference_dir=./inference_model/det_model/
- 导出识别模型
python .\\tools\\export_model.py -c .\\Temp\\configs\\en_PP-OCRv4_rec.yml -o Global.pretrained_model=.\\output/en_PP-OCRv4_rec/best_accuracy Global.save_inference_dir=./inference_model/rec_model/
3. 测试模型
import os
from paddleocr import PaddleOCR
from PIL import Image
from paddleocr.tools.infer.utility import draw_ocr
# 初始化OCR模型
ocr = PaddleOCR(
lang="ch",
use_gpu=False,
det_model_dir="inference_model/v3det_model/Student",
rec_model_dir="inference_model/rec_model",
rec_char_dict_path='inference_model/en_dict.txt',
# det_db_thresh=0.1, # 文字检测阈值 默认0.3
# det_db_box_thresh=0.1, # 框后处理阈值
# det_db_unclip_ratio=3.0, # 扩展框比例,值太小可能导致框过小或断裂
)
# 输入文件夹路径
img_folder = 'testImages'
output_folder = 'results_with_boxes'
os.makedirs(output_folder, exist_ok=True)
img_extensions = ['.png', '.jpg', '.jpeg']
for filename in os.listdir(img_folder):
if any(filename.lower().endswith(ext) for ext in img_extensions):
img_path = os.path.join(img_folder, filename)
print(f"Processing: {img_path}")
img = Image.open(img_path).convert('RGB')
result = ocr.ocr(img_path)
# 输出识别结果和置信度
for line in result[0]:
text = line[1][0]
score = line[1][1]
print(f"{filename}\\t{text}\\t{score:.4f}")
# 画图:检测框坐标和文字内容
boxes = [line[0] for line in result[0]] # 检测框坐标
texts = [line[1][0] for line in result[0]] # 识别文本
scores = [line[1][1] for line in result[0]] # 置信度
# PaddleOCR自带的绘图工具画图
img_with_boxes = draw_ocr(img, boxes, texts, scores)
# 保存图片
img_with_boxes = Image.fromarray(img_with_boxes)
save_path = os.path.join(output_folder, f"{os.path.splitext(filename)[0]}_with_boxes.png")
img_with_boxes.save(save_path)
print(f"Saved result to: {save_path}\\n")
4. 虚拟环境
conda activate paddle38
5.模型使用
时间:2025/10/10
环境
paddleocr 2.8.1
paddlepaddle-gpu 2.6.2
paddlex 3.2.1
代码test Model.py
import os
import sys
import argparse
import json
from paddleocr import PaddleOCR
def main():
parser = argparse.ArgumentParser(description="Single image OCR")
parser.add_argument("image_path", help="输入图片路径")
args = parser.parse_args()
image_path = args.image_path
if not os.path.isfile(image_path):
print(json.dumps({
"success": False,
"error": f"文件不存在: {image_path}"
}, ensure_ascii=False))
sys.exit(1)
try:
# PaddleOCR 2.8.1 调用训练模型
ocr = PaddleOCR(
use_gpu=True,
det_model_dir=r"D:\\Files\\PythonProject2\\src\\main\\resources\\models\\det_model_v3\\Student",
rec_model_dir=r"D:\\Files\\PythonProject2\\src\\main\\resources\\models\\rec_model_v4",
rec_char_dict_path=r"D:\\Files\\PythonProject2\\src\\main\\resources\\models\\en_dict.txt"
)
result = ocr.ocr(image_path, cls=True)
lines = []
full_text = ""
for line in result[0]:
box = line[0]
text = line[1][0]
score = line[1][1]
full_text += text
lines.append({
"box": box,
"text": text,
"score": score
})
print(json.dumps({
"success": True,
"full_text": full_text.strip(),
"lines": lines
}, ensure_ascii=False))
except Exception as e:
print(json.dumps({
"success": False,
"error": f"OCR处理失败: {str(e)}"
}, ensure_ascii=False))
sys.exit(2)
if __name__ == "__main__":
main()
执行
PS D:\\Files\\PythonProject2> python .\\testModel.py .\\img.png
[2025/10/10 13:37:41] ppocr DEBUG: Namespace(help='==SUPPRESS==', use_gpu=True, use_xpu=False, use_npu=False, use_mlu=False, ir_optim=True, use_tensorrt=False, min_subgraph_size=15, precision='fp32', gpu_mem=500, gpu_id=0, image_dir=None, page_num=0, det_algorithm='DB', det_model_dir='D:\\\\Files\\\\PythonProject2\\\\src\\\\main\\\\resources\\\\models\\\\det_model_v3\\\\Student', det_limit_side_len=960, det_limit_type='max', det_box_type='quad', det_db_thresh=0.3, det_db_box_thresh=0.6, det_db_unclip_ratio=1.5, max_batch_size=10, use_dilation=False, det_db_score_mode='fast', det_east_score_thresh=0.8, det_east_cover_thresh=0.1, det_east_nms_thresh=0.2, det_sast_score_thresh=0.5, det_sast_nms_thresh=0.2, det_pse_thresh=0, det_pse_box_thresh=0.85, det_pse_min_area=16, det_pse_scale=1, scales=[8, 16, 32], alpha=1.0, beta=1.0, fourier_degree=5, rec_algorithm='SVTR_LCNet', rec_model_dir='D:\\\\Files\\\\PythonProject2\\\\src\\\\main\\\\resources\\\\models\\\\rec_model_v4', rec_image_inverse=True, rec_image_shape='3, 48, 320', rec_batch_num=6, max_text_length=25, rec_char_dict_path='D:\\\\Files\\\\PythonProject2\\\\src\\\\main\\\\resources\\\\models\\\\en_dict.txt', use_space_char=True, vis_font_path='./doc/fonts/simfang.ttf', drop_score=0.5, e2e_algorithm='PGNet', e2e_model_dir=None, e2e_limit_side_len=768, e2e_limit_type='max', e2e_pgnet_score_thresh=0.5, e2e_char_dict_path='./ppocr/utils/ic15_dict.txt', e2e_pgnet_valid_set='totaltext', e2e_pgnet_mode='fast', use_angle_cls=False, cls_model_dir='C:\\\\Users\\\\33226/.paddleocr/whl\\\\cls\\\\ch_ppocr_mobile_v2.0_cls_infer', cls_image_shape='3, 48, 192', label_list=['0', '180'], cls_batch_num=6, cls_thresh=0.9, enable_mkldnn=False, cpu_threads=10, use_pdserving=False, warmup=False, sr_model_dir=None, sr_image_shape='3, 32, 128', sr_batch_num=1, draw_img_save_dir='./inference_results', save_crop_res=False, crop_res_save_dir='./output', use_mp=False, total_process_num=1, process_id=0, benchmark=False, save_log_path='./log_output/', show_log=True, use_onnx=False, return_word_box=False, output='./output', table_max_len=488, table_algorithm='TableAttn', table_model_dir=None, merge_no_span_structure=True, table_char_dict_path=None, layout_model_dir=None, layout_dict_path=None, layout_score_threshold=0.5, layout_nms_threshold=0.5, kie_algorithm='LayoutXLM', ser_model_dir=None, re_model_dir=None, use_visual_backbone=True, ser_dict_path='../train_data/XFUND/class_list_xfun.txt', ocr_order_method=None, mode='structure', image_orientation=False, layout=True, table=True, ocr=True, recovery=False, use_pdf2docx_api=False, invert=False, binarize=False, alphacolor=(255, 255, 255), lang='ch', det=True, rec=True, type='ocr', savefile=False, ocr_version='PP-OCRv4', structure_version='PP-StructureV2')
[2025/10/10 13:37:45] ppocr WARNING: Since the angle classifier is not initialized, it will not be used during the forward process
[2025/10/10 13:37:46] ppocr DEBUG: dt_boxes num : 5, elapsed : 1.3364863395690918
[2025/10/10 13:37:46] ppocr DEBUG: rec_res num : 5, elapsed : 0.13319826126098633
{"success": true, "full_text": "0317WS2022D100012", "lines": [{"box": [[16.0, 4.0], [122.0, 4.0], [122.0, 83.0], [16.0, 83.0]], "text": "0317", "score": 0.8762916922569275}, {"box": [[148.0, 11.0], [248.0, 11.0], [248.0, 82.0], [148.0, 82.0]], "text": "WS", "score": 0.9998351335525513}, {"box": [[252.0, 17.0], [379.0, 12.0], [382.0, 81.0], [256.0, 86.0]], "text": "2022", "score": 0.9991670250892639}, {"box": [[432.0, 18.0], [524.0, 23.0], [521.0, 83.0], [429.0, 79.0]], "text": "D10", "score": 0.9650375247001648}, {"box": [[16.0, 90.0], [114.0, 90.0], [114.0, 151.0], [16.0, 151.0]], "text": "0012", "score": 0.9996055960655212}]}
6. 检测模型参数量
import paddle
import os
def count_inference_model_params(model_prefix: str, use_gpu=False):
"""
统计 Paddle 推理模型 (.pdmodel + .pdiparams) 参数总量
model_prefix: 文件前缀,例如 D:\\...\\rec_model_v4\\inference
"""
if not os.path.exists(model_prefix + ".pdmodel") or not os.path.exists(model_prefix + ".pdiparams"):
raise FileNotFoundError(f"找不到模型文件: {model_prefix}.pdmodel 或 {model_prefix}.pdiparams")
paddle.enable_static()
place = paddle.CUDAPlace(0) if use_gpu else paddle.CPUPlace()
exe = paddle.static.Executor(place)
inference_program, feed_target_names, fetch_targets = paddle.static.load_inference_model(
path_prefix=model_prefix, executor=exe
)
total_params = 0
for block in inference_program.blocks:
for var in block.vars.values():
if var.persistable and var.name not in feed_target_names:
try:
shape = var.shape
except RuntimeError:
continue
param_count = 1
for dim in shape:
param_count *= dim
total_params += param_count
return total_params
if __name__ == "__main__":
det_model_prefix = r"D:\\Files\\PythonProject2\\src\\main\\resources\\models\\det_model_v3\\Student\\inference"
rec_model_prefix = r"D:\\Files\\PythonProject2\\src\\main\\resources\\models\\rec_model_v4\\inference"
det_params = count_inference_model_params(det_model_prefix, use_gpu=False)
rec_params = count_inference_model_params(rec_model_prefix, use_gpu=False)
print(f"检测模型参数量: {det_params}")
print(f"识别模型参数量: {rec_params}")
输出
PS D:\\Files\\PythonProject2> python .\\testModelsCanShu.py
I1010 13:56:04.597359 3416 program_interpreter.cc:212] New Executor is Running.
检测模型参数量: 592625
识别模型参数量: 1890532
临时记录
start_epoch:188 验证集评估结果
[2025/06/25 16:15:36] ppocr INFO: resume from .\\output\\en_PP-OCRv4_rec\\latest
[2025/06/25 16:15:36] ppocr INFO: metric in ckpt ***************
[2025/06/25 16:15:36] ppocr INFO: acc:0
[2025/06/25 16:15:36] ppocr INFO: is_float16:False
[2025/06/25 16:15:36] ppocr INFO: start_epoch:188
[2025/06/25 16:15:39] ppocr INFO: metric eval ***************
[2025/06/25 16:15:39] ppocr INFO: acc:0.9583332834201415
[2025/06/25 16:15:39] ppocr INFO: norm_edit_dis:0.9878472228551793
[2025/06/25 16:15:39] ppocr INFO: fps:63.97288645081185
[2025/06/26 09:05:29] ppocr INFO: resume from .\\output\\en_PP-OCRv4_rec\\latest
[2025/06/26 09:05:29] ppocr INFO: metric in ckpt ***************
[2025/06/26 09:05:29] ppocr INFO: acc:0
[2025/06/26 09:05:29] ppocr INFO: is_float16:False
[2025/06/26 09:05:29] ppocr INFO: start_epoch:301
[2025/06/26 09:05:30] ppocr INFO: metric eval ***************
[2025/06/26 09:05:30] ppocr INFO: acc:0.9635416164822075
[2025/06/26 09:05:30] ppocr INFO: norm_edit_dis:0.9891493061206958
[2025/06/26 09:05:30] ppocr INFO: fps:265.29454544496195
[2025/06/25 18:24:53] ppocr INFO: epoch: [270/300], global_step: 300, lr: 0.000058, acc: 1.000000, norm_edit_dis: 1.0
00000, CTCLoss: 0.049039, NRTRLoss: 0.620189, loss: 0.669288, avg_reader_cost: 0.06627 s, avg_batch_cost: 8.51739 s, avg_samples: 70.4, ips: 8.26544 samples/s, eta: 0:39:29, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:25:28] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:25:28] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\iter_epoch_270
[2025/06/25 18:26:19] ppocr INFO: epoch: [271/300], global_step: 310, lr: 0.000057, acc: 1.000000, norm_edit_dis: 1.0
00000, CTCLoss: 0.048249, NRTRLoss: 0.620180, loss: 0.668467, avg_reader_cost: 0.11603 s, avg_batch_cost: 8.57698 s, avg_samples: 72.0, ips: 8.39456 samples/s, eta: 0:37:53, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:26:36] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:27:45] ppocr INFO: epoch: [272/300], global_step: 320, lr: 0.000055, acc: 0.989583, norm_edit_dis: 0.9
99132, CTCLoss: 0.059071, NRTRLoss: 0.620167, loss: 0.679213, avg_reader_cost: 0.07585 s, avg_batch_cost: 8.61765 s, avg_samples: 68.8, ips: 7.98361 samples/s, eta: 0:36:19, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:27:45] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:28:54] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:29:11] ppocr INFO: epoch: [274/300], global_step: 330, lr: 0.000053, acc: 0.994792, norm_edit_dis: 0.9
99566, CTCLoss: 0.057062, NRTRLoss: 0.620193, loss: 0.677321, avg_reader_cost: 0.13713 s, avg_batch_cost: 8.65757 s, avg_samples: 70.4, ips: 8.13162 samples/s, eta: 0:34:36, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:30:03] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:30:37] ppocr INFO: epoch: [275/300], global_step: 340, lr: 0.000051, acc: 1.000000, norm_edit_dis: 1.0
00000, CTCLoss: 0.058556, NRTRLoss: 0.620187, loss: 0.678740, avg_reader_cost: 0.07255 s, avg_batch_cost: 8.54815 s, avg_samples: 72.0, ips: 8.42288 samples/s, eta: 0:33:00, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:31:12] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:32:02] ppocr INFO: epoch: [276/300], global_step: 350, lr: 0.000049, acc: 0.994792, norm_edit_dis: 0.9
99566, CTCLoss: 0.062293, NRTRLoss: 0.620185, loss: 0.682432, avg_reader_cost: 0.06702 s, avg_batch_cost: 8.54973 s, avg_samples: 73.6, ips: 8.60846 samples/s, eta: 0:31:25, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:32:20] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:33:28] ppocr INFO: epoch: [277/300], global_step: 360, lr: 0.000048, acc: 0.994792, norm_edit_dis: 0.9
99566, CTCLoss: 0.053074, NRTRLoss: 0.620199, loss: 0.673219, avg_reader_cost: 0.06782 s, avg_batch_cost: 8.59742 s, avg_samples: 67.2, ips: 7.81629 samples/s, eta: 0:29:51, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:33:29] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:34:37] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:34:54] ppocr INFO: epoch: [279/300], global_step: 370, lr: 0.000046, acc: 0.994792, norm_edit_dis: 0.9
99566, CTCLoss: 0.045486, NRTRLoss: 0.620186, loss: 0.667856, avg_reader_cost: 0.12697 s, avg_batch_cost: 8.59989 s, avg_samples: 70.4, ips: 8.18615 samples/s, eta: 0:28:07, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:35:46] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:36:20] ppocr INFO: epoch: [280/300], global_step: 380, lr: 0.000044, acc: 0.989583, norm_edit_dis: 0.9
99092, CTCLoss: 0.057158, NRTRLoss: 0.620180, loss: 0.677308, avg_reader_cost: 0.07080 s, avg_batch_cost: 8.54077 s, avg_samples: 73.6, ips: 8.61749 samples/s, eta: 0:26:32, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:36:54] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:36:55] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\iter_epoch_280
[2025/06/25 18:37:46] ppocr INFO: epoch: [281/300], global_step: 390, lr: 0.000043, acc: 0.989583, norm_edit_dis: 0.9
99006, CTCLoss: 0.057158, NRTRLoss: 0.620190, loss: 0.677308, avg_reader_cost: 0.11939 s, avg_batch_cost: 8.60828 s, avg_samples: 72.0, ips: 8.36404 samples/s, eta: 0:24:57, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:38:04] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:39:11] ppocr INFO: epoch: [282/300], global_step: 400, lr: 0.000041, acc: 0.984375, norm_edit_dis: 0.9
98639, CTCLoss: 0.056775, NRTRLoss: 0.620197, loss: 0.677154, avg_reader_cost: 0.07201 s, avg_batch_cost: 8.55105 s, avg_samples: 67.2, ips: 7.85869 samples/s, eta: 0:23:22, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:39:12] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:40:21] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:40:38] ppocr INFO: epoch: [284/300], global_step: 410, lr: 0.000039, acc: 0.984375, norm_edit_dis: 0.9
98639, CTCLoss: 0.053467, NRTRLoss: 0.620176, loss: 0.673645, avg_reader_cost: 0.13797 s, avg_batch_cost: 8.66229 s, avg_samples: 73.6, ips: 8.49660 samples/s, eta: 0:21:39, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:41:30] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:42:04] ppocr INFO: epoch: [285/300], global_step: 420, lr: 0.000038, acc: 0.989583, norm_edit_dis: 0.9
98875, CTCLoss: 0.058270, NRTRLoss: 0.620152, loss: 0.678415, avg_reader_cost: 0.07106 s, avg_batch_cost: 8.63264 s, avg_samples: 72.0, ips: 8.34044 samples/s, eta: 0:20:05, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:42:39] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:43:58] ppocr INFO: epoch: [286/300], global_step: 430, lr: 0.000036, acc: 0.994792, norm_edit_dis: 0.9
99527, CTCLoss: 0.053610, NRTRLoss: 0.620160, loss: 0.676677, avg_reader_cost: 0.07294 s, avg_batch_cost: 11.40486 s, avg_samples: 70.4, ips: 6.17281 samples/s, eta: 0:18:38, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:44:18] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:45:32] ppocr INFO: epoch: [287/300], global_step: 440, lr: 0.000035, acc: 1.000000, norm_edit_dis: 1.0
00000, CTCLoss: 0.044965, NRTRLoss: 0.620161, loss: 0.665135, avg_reader_cost: 0.06975 s, avg_batch_cost: 9.39042 s, avg_samples: 68.8, ips: 7.32662 samples/s, eta: 0:17:05, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:45:33] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:46:48] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:47:07] ppocr INFO: epoch: [289/300], global_step: 450, lr: 0.000033, acc: 1.000000, norm_edit_dis: 1.0
00000, CTCLoss: 0.045696, NRTRLoss: 0.620164, loss: 0.665892, avg_reader_cost: 0.14613 s, avg_batch_cost: 9.47883 s, avg_samples: 73.6, ips: 7.76467 samples/s, eta: 0:15:23, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:48:03] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:48:40] ppocr INFO: epoch: [290/300], global_step: 460, lr: 0.000032, acc: 1.000000, norm_edit_dis: 1.0
00000, CTCLoss: 0.047539, NRTRLoss: 0.620172, loss: 0.667690, avg_reader_cost: 0.06608 s, avg_batch_cost: 9.31875 s, avg_samples: 70.4, ips: 7.55466 samples/s, eta: 0:13:48, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:49:18] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:49:19] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\iter_epoch_290
[2025/06/25 18:50:14] ppocr INFO: epoch: [291/300], global_step: 470, lr: 0.000031, acc: 1.000000, norm_edit_dis: 1.0
00000, CTCLoss: 0.049244, NRTRLoss: 0.620185, loss: 0.669500, avg_reader_cost: 0.11283 s, avg_batch_cost: 9.36815 s, avg_samples: 72.0, ips: 7.68562 samples/s, eta: 0:12:13, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
[2025/06/25 18:50:33] ppocr INFO: save model in ./output/en_PP-OCRv4_rec\\latest
[2025/06/25 18:51:48] ppocr INFO: epoch: [292/300], global_step: 480, lr: 0.000029, acc: 0.994792, norm_edit_dis: 0.9
99132, CTCLoss: 0.052151, NRTRLoss: 0.620176, loss: 0.672631, avg_reader_cost: 0.07306 s, avg_batch_cost: 9.35568 s, avg_samples: 68.8, ips: 7.35382 samples/s, eta: 0:10:38, max_mem_reserved: 12193 MB, max_mem_allocated: 11824 MB
安装依赖
python -m pip install scikit-image imgaug lmdb rapidfuzz -i <https://mirrors.aliyun.com/pypi/simple/>
python -m pip install "numpy<2.0" --force-reinstall -i <https://mirrors.aliyun.com/pypi/simple/>